I’ve seen a lot of failed machine learning models in the course of my work. I’ve worked with a number of organizations to build both models and the teams and culture to support them. And in my experience, the number one reason models fail is because the team failed to create a minimum viable product (MVP).
In fact, skipping the MVP phase of product development is how one legacy corporation ended up dissolving its entire analytics team. The nascent team followed the lead of its manager and chose to use a NoSQL database, despite the fact no one on the team had NoSQL expertise. The team built a model, then attempted to scale the application. However, because it tried to scale its product using technology that was inappropriate for the use case, it never delivered a product to its customers. The company leadership never saw a return on its investment and concluded that investing in a data initiative was too risky and unpredictable.
If that data team had started with an MVP, not only could it have diagnosed the problem with its model but it could also have switched to the cheaper, more appropriate technology alternative and saved money.
In traditional software development, MVPs are a common part of the “lean” development cycle; they’re a way to explore a market and learn about the challenges related to the product. Machine learning product development, by contrast, is struggling to become a lean discipline because it’s hard to learn quickly and reliably from complex systems.
Yet, for ML teams, building an MVP remains an absolute must. If the weakness in the model originates from bad data quality, all further investments to improve the model will be doomed to failure, no matter the amount of money thrown at the project. Similarly, if the model underperforms because it was not deployed or monitored properly, then any money spent on improving data quality will be wasted. Teams can avoid these pitfalls by first developing an MVP and by learning from failed attempts.
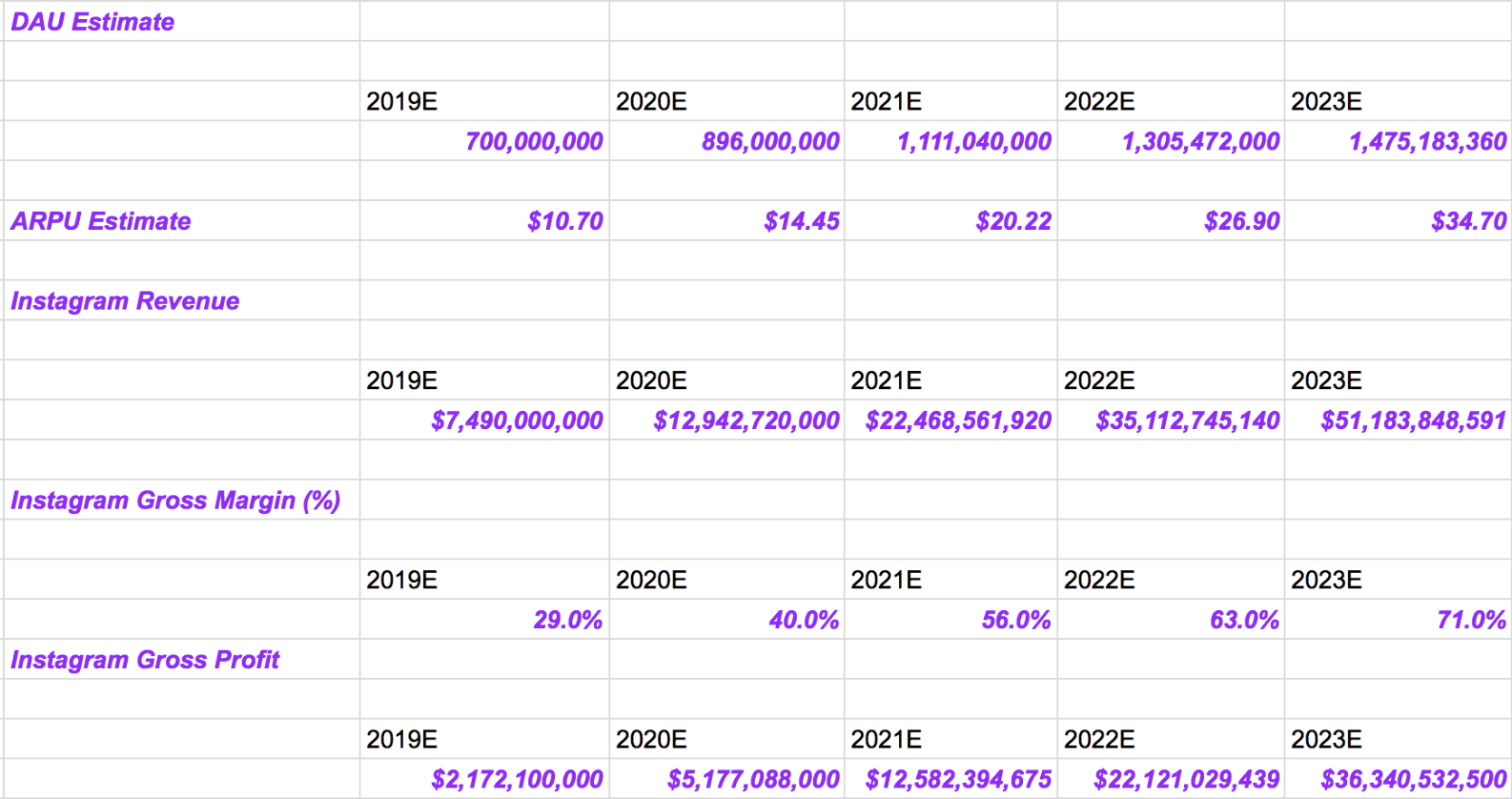
Return on investment in machine learning
Machine learning initiatives require tremendous overhead work, such as the design of new data pipelines, data management frameworks, and data monitoring systems. That overhead work causes an ‘S’-shaped return-on-investment curve, which most tech leaders are not accustomed to. Company leaders who don’t understand that this S-shaped ROI is inherent to machine learning projects could abandon projects prematurely, judging them to be failures.

Above: The return-on-investment curve of Machine Learning initiatives shows an S-curve compared to traditional Software Development projects, which have a more linear ROI.
Unfortunately, prematurely terminating a project happens in the “building the foundations” phase of the ROI curve, and many organizations never allow their teams to progress far enough into the next phases.
Failed models offer good lessons
Identifying the weaknesses of any product sooner rather than later can result in hundreds of thousands of dollars in savings. Spotting potential shortcomings ahead of time is even more important with data products, because the root causes for a subpar recommendation system, for instance, could be anything from technology choices to data quality and/or quantity to model performance to integration, and more. To avoid bleeding resources, early diagnosis is key.
For instance, by foregoing the MVP stage of machine learning development, one company deploying a new search algorithm missed the opportunity to identify the poor quality of its data. In the process, it lost customers to the competition and had to not only fix its data collection process but eventually redo every subsequent step, including model development. This resulted in investments in the wrong technologies and six months’ worth of man hours for a team of 10 engineers and data scientists. It also led to the resignation of several key members on that team. Each departed employee cost $70,000 per person to replace.
In another example, a company leaned too heavily on A/B testing to determine the viability of its model. A/B tests are an incredible instrument for probing the market; they are a particularly relevant tool for machine learning products, as those products are often built using theoretical metrics that do not always closely relate to real-life success. However, many companies use A/B tests to identify the weaknesses in their machine learning algorithms. By using A/B tests as a quality assurance (QA) checkpoint, companies miss the opportunity to stop poorly developed models and systems in their tracks before sending a prototype to production. The typical ML prototype takes 12 to 15 engineer-weeks to turn into a real product. Based on that projection, failing to first create an MVP will typically result in a loss of over $50,000 if the final product isn’t successful.
The investment you’re protecting
Personnel costs are just one consideration. Let’s step back and discuss the wider investment in AI that you need to protect by first building an MVP.
Data collection. Data acquisition costs will vary based on the type of product your building and how frequently you’re gathering and updating data. If you are developing an application for an IoT device, you will have to identify which data to keep on the edge vs. which data to store remotely on the cloud where your team can do a lot of R&D work on it. If you are in the eCommerce business, gathering data will mean adding new front-end instrumentation to your website, which will unquestionably slow down the response time and degrade the overall user experience, potentially costing you customers.
Data pipeline building. The creation of pipelines to transfer data is fortunately a one-time initiative, but it is also a costly and time-consuming one.
Data storage. The consensus for a while now has been that data storage is being progressively commoditized. However, there are more and more indications that Moore’s Law just isn’t enough anymore to make up for the growth rate of the volumes of data we collect. If those trends prove true, storage will become increasingly expensive and will require that we stick to the bare minimum: only the data that is truly informational and actionable.
Data cleaning. With volumes always on the rise, the amount of data that is available to data scientists is becoming both an opportunity and a liability. Separating the wheat from the chaff is often difficult and time-consuming. And since these decisions typically need to be made by the data scientist in charge of developing the model, the process is all the more costly.
Data annotation. Using larger amounts of data requires more labels, and using crowds of human annotators isn’t enough anymore. Semi-automated labeling and active learning are becoming increasingly attractive to many companies, especially those with very large volumes of data. However the licenses to those platforms can represent a substantial add to the entire price of your ML initiative, especially when your data shows important seasonal patterns and needs to be relabeled regularly.
Compute power. Just like data storage, computer power is becoming commoditized, and many companies opt for cloud-based solutions such as AWS or GCP. However, with large volumes of data and complex models, the bill can become a considerable part of the entire budget and can sometimes even require a hefty investment in a server solution.
Modeling cost. The model development phase accounts for the most unpredictable cost in your final bill because the amount of time required to build a model depends on many different factors: the skill of your ML team, problem complexity, required accuracy, data quality, time constraints, and even luck. Hyperparameter tuning for deep learning is making things even more hectic, as this phase of development benefits little from experience, and usually only a trial-and-error approach prevails. Typical models will take about six weeks of development for a mid-level data scientist, so that’s about $15K in salary alone.
Deployment cost. Depending on the organization, this phase can either be fast or slow. If the company is mature from an ML-perspective and already has a standardized path to production, deploying a model will likely take about two weeks of time by an ML engineer, so about $5K. However, more often than not, you’ll require custom work, and that can make the deployment phase the most time-consuming and expensive part of creating a live ML MVP.

Above: The pyramid of needs for machine learning.
The cost of diagnosis
Recent years have seen an explosion in the number of ML projects powered by deep learning architectures. But along with the fantastic promise of deep learning comes the most frightening challenge in machine learning: lack of explainability. Deep learning models can have tens, if not hundreds of thousands, of parameters, and this makes it impossible for data scientists to use intuition when trying to diagnose problems with the system. This is likely one of the chief reasons ineffective models are taken offline rather than fixed and improved. If, after weeks waiting for the ML team to diagnose a mistake, they still can’t find the problem, it’s easiest to move on and start over.
And because most data scientists are trained as researchers rather than engineers, their core expertise as well as their interest rarely lies in improving systems but rather in exploring new ideas. Pushing your data science experts to spend most of their time “fixing” things (which could cost you 70 percent of your R&D budget) could considerably increase the churn among them. Ultimately, debugging, or even incremental improvement of an ML MVP can prove much more costly than a similarly-sized “traditional” software engineering MVP.
Yet ML MVPs remain an absolute must, because if the weakness in the model originates in the bad quality of the data, all further investments to improve the model will be doomed to failure, no matter how much money you throw at the project. Similarly, if the model underperforms because it was not deployed or monitored properly, then any money spent on improving data quality will be wasted.
How to succeed with an MVP
But there is hope. It is just a matter of time until the lean methodology that has seen huge success within the software development community proves itself useful for machine learning projects as well. For this to happen, though, we’ll have to see a shift in mindset among data scientists, a group known to value perfectionism over short time-to-market. Business leaders will also need to understand the subtle differences between an engineering and a machine learning MVP:
Data scientists need to evaluate the data and the model separately. The fact that the application is not providing the desired results might be caused by one or the other, or both, and diagnosing can never converge unless data scientists keep this fact in mind. Because data scientists now have the option of improving their data collecting process, they can do justice to those models that would have been otherwise identified as hopeless.
Be patient with ROI. Because the ROI curve of ML is S-shaped, even MVPs require more way work than you could typically anticipate. As we have seen, ML products require many complex steps to reach completion, and this is something that needs to be profusely communicated to stakeholders to limit the risk of frustration and premature abandonment of a project.
Diagnosing is costly but critical. Debugging ML systems is almost always extremely time-consuming, in particular because of the lack of explainability in many modern models (DL). Building from scratch is cheaper but is a worse financial bet because humans have a natural tendency to repeat the same mistakes anyway. Obtaining the right diagnostic will ensure your ML team knows with precision what requires attention (whether it be the data, the model, or the deployment), allowing you to prevent the costs of the project from exploding. Diagnosing problems also gives your team the opportunity to learn valuable lessons from their mistakes, potentially shortening future project cycles. Failed models can be a mine of information; redesigning from scratch is thus often a lost opportunity.
Make sure no single person has the keys to your project. Unfortunately, extremely short tenures are the norm among machine learning employees. When key team members leave a project, its problems are even harder to diagnose, so company leaders must ensure that “tribal” knowledge is not owned by any one single person on the team. Otherwise, even the most promising MVPs will have to be abandoned. Make sure that once your MVP is ready for the market, you start gathering data as fast as possible and that learnings from the project are shared with your entire team.
No shortcuts
No matter how long you have worked in the field, ML models are daunting, especially when the data is highly dimensional and high volume. For the highest chances of success, you need to test your model early with an MVP and invest the necessary time and money in diagnosing and fixing its weaknesses. There are no shortcuts.
Jennifer Prendki is VP of Machine Learning at Figure Eight.
from VentureBeat https://venturebeat.com
via IFTTT
 Psychology's "reproducibility crisis" grows, as Many Labs 2, a global collaboration of scientists attempting to replicate the results of hyped psychology experiments past, continues to fail (or succeed, depending on how you look at it). In attempting to "replicate 28 classic and contemporary published findings," the group was only able to do so around half of the time.
Psychology's "reproducibility crisis" grows, as Many Labs 2, a global collaboration of scientists attempting to replicate the results of hyped psychology experiments past, continues to fail (or succeed, depending on how you look at it). In attempting to "replicate 28 classic and contemporary published findings," the group was only able to do so around half of the time. FREE MINDS
FREE MINDS